In the wild world of cryptocurrency trading, where prices can swing wildly in seconds, high-frequency trading (HFT) has become the go-to strategy for those looking to capitalize on tiny market inefficiencies. But traditional HFT algorithms, often rule-based or reliant on simple statistical models, are starting to show their limits in the chaotic crypto landscape. Enter reinforcement learning (RL)—a branch of artificial intelligence that’s revolutionizing how machines learn to trade. RL agents don’t just follow pre-set rules; they learn from trial and error, adapting to the market’s unpredictability like a seasoned trader honing their instincts over years of experience.
This article dives into how RL is being applied to HFT in crypto, exploring its mechanics, real-world applications, challenges, and future potential. Whether you’re a developer tinkering with algorithms or an investor curious about the tech behind the trades, we’ll break it down step by step, with some practical insights and data to keep things grounded.
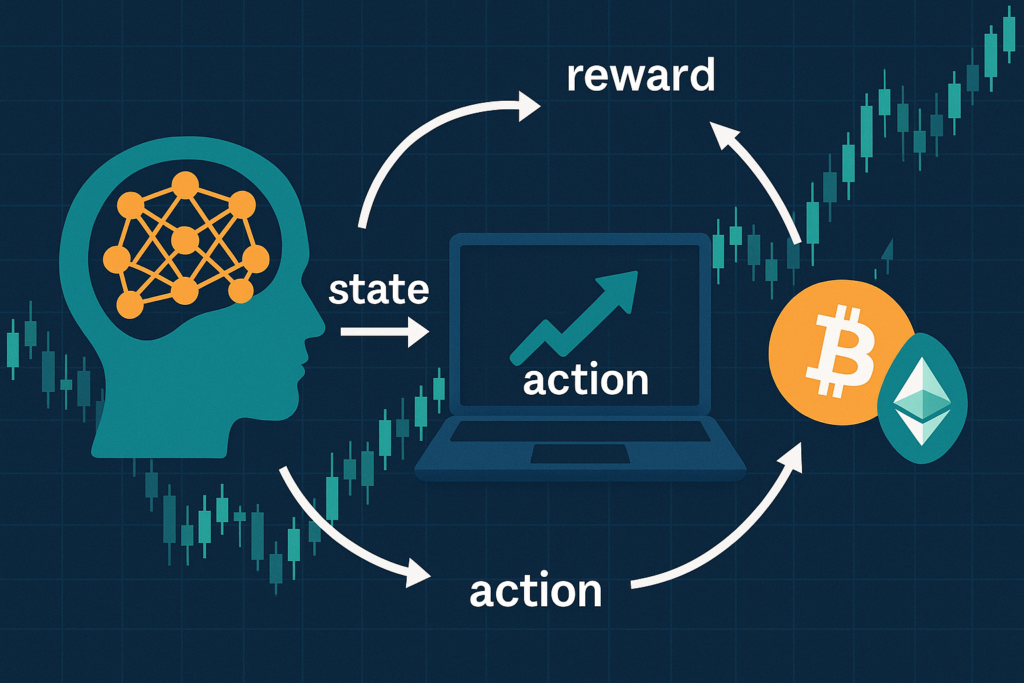
Understanding the Basics: What is Reinforcement Learning?
At its core, reinforcement learning is about teaching an AI agent to make decisions by rewarding good outcomes and penalizing bad ones. Imagine training a dog: a treat for sitting on command, a stern “no” for chewing the furniture. In RL, the “agent” interacts with an “environment” (like a simulated crypto market), takes actions (buy, sell, hold), observes the results (profit or loss), and receives rewards based on performance.
Key components include:
- State: The current market snapshot—prices, volumes, order books, etc.
- Action: Decisions like placing a limit order or executing a trade.
- Reward: A score, often tied to profit minus fees, that guides learning.
- Policy: The strategy the agent develops over time.
Unlike supervised learning, where models learn from labeled data, RL thrives in dynamic settings where the best move isn’t always obvious. This makes it perfect for crypto, where external factors like news or whale movements can flip the script instantly.
High-Frequency Trading in Crypto: The Need for Speed and Smarts
HFT involves executing thousands of trades per second, exploiting micro-inefficiencies like price discrepancies across exchanges. In crypto, this is amplified by 24/7 markets, low barriers to entry, and extreme volatility—Bitcoin can drop 10% in minutes, creating fleeting opportunities.
Traditional HFT relies on strategies like arbitrage, market making, or momentum trading. But crypto’s lack of regulation and high noise levels make it tough. Slippage, latency, and flash crashes can wipe out gains. That’s where RL shines: it can optimize order placement, manage inventory, and adapt to changing conditions in real-time.
For instance, RL agents can learn to place limit orders at optimal depths in the order book, balancing the risk of non-execution against potential profits. Studies show RL can reduce execution costs by up to 20% in simulated environments compared to benchmark strategies.
How RL Powers High-Frequency Crypto Trades
Applying RL to HFT starts with building a realistic environment. Tools like Gym from OpenAI or custom simulators use historical tick data to mimic exchanges. Agents train on millions of episodes, learning to navigate bull runs, bear markets, and everything in between.
Popular approaches include:
- Deep Q-Networks (DQN): Great for discrete actions, like choosing buy/sell quantities. They estimate the value of actions in given states.
- Proximal Policy Optimization (PPO): A policy-gradient method that’s stable and efficient for continuous action spaces, ideal for adjusting trade sizes dynamically.
- Actor-Critic Methods: Combine value estimation with policy optimization for faster convergence.
In crypto-specific setups, features might include order book depth, recent trade volumes, volatility indicators (e.g., Bollinger Bands), and even sentiment from social media. Rewards are often shaped to encourage low-risk, high-reward trades—think profit adjusted for transaction costs and slippage.
One innovative twist is hierarchical RL, where a high-level agent sets strategies (e.g., aggressive vs. conservative), and low-level agents handle execution. This is particularly useful in HFT, where decisions span milliseconds to minutes.
Table 1: Common RL Algorithms for Crypto HFT
| Algorithm | Type | Strengths | Weaknesses | Example Use Case |
|---|---|---|---|---|
| DQN | Value-Based | Handles high-dimensional states well; good for exploration. | Prone to overestimation; discrete actions only. | Arbitrage between exchanges like Binance and Coinbase. |
| PPO | Policy-Based | Stable training; handles continuous actions. | Computationally intensive. | Dynamic order sizing in volatile pairs like ETH/USDT. |
| A2C/A3C | Actor-Critic | Parallel training speeds up learning; balances exploration/exploitation. | Sensitive to hyperparameters. | Market making with inventory management. |
| SAC | Off-Policy | Efficient with entropy regularization for better exploration. | Complex to implement. | Pair trading in correlated assets like BTC/ETH. |
This table highlights how different algorithms suit various HFT scenarios, based on recent implementations.
Real-World Applications and Case Studies
RL isn’t just theoretical—it’s hitting the crypto trenches. A 2025 study on cryptocurrency futures used RL to optimize portfolios, achieving higher Sharpe ratios than traditional methods by adapting to uncertainty. Another combined RL with technical analysis for trend monitoring, outperforming benchmarks in backtests on Bitcoin and Ethereum.
In pair trading, RL agents learn to scale positions dynamically, adjusting based on spread deviations. One paper showed annualized returns of 9-31% in crypto pairs, beating static strategies. Tools like FinRL even host contests for RL-based trading, with 2023-2025 editions focusing on crypto tasks.
On X (formerly Twitter), traders share experiments: one user trained an RL agent on crypto futures that learned… to do nothing, highlighting the importance of reward design. Others discuss hybrid models blending RL with wavelets for S&P futures, adaptable to crypto.
Table 2: Performance Metrics from Recent RL Crypto HFT Studies (2024-2025)
| Study Focus | Algorithm | Annualized Return | Sharpe Ratio | Drawdown | Data Period |
|---|---|---|---|---|---|
| Futures Portfolio Optimization | Custom RL | 15-25% | 1.2-1.8 | <15% | 2024-2025 |
| Pair Trading with Dynamic Scaling | PPO/DQN | 9.94-31.53% | 0.8-1.5 | 10-20% | 2023-2025 |
| Order Placement Optimization | Deep RL | Cost Reduction: 20% | N/A | N/A | 18 months (2023-2024) |
| Wavelet-Enhanced DRL | DRL Variants | 12-18% | 1.0-1.4 | <10% | S&P Futures (adaptable to crypto) |
These metrics, drawn from peer-reviewed work, show RL’s edge but also variability due to market conditions.
Challenges in Deploying RL for Crypto HFT
Despite the hype, RL isn’t a silver bullet. Overfitting is a big issue—agents excel in backtests but flop live due to unseen volatility. Crypto data is noisy, with fat tails and regime shifts that trip up models.
Other hurdles:
- Computational Demands: Training on high-frequency data requires GPUs and can take days.
- Reward Engineering: Poorly designed rewards lead to unwanted behaviors, like excessive trading.
- Regulatory and Ethical Concerns: In crypto’s gray areas, RL could amplify market manipulation if misused.
- Non-Stationarity: Markets evolve, so agents need continual retraining.
Recent advances, like feature enrichment to handle sparse HFT data, are addressing these. Hybrid models combining RL with supervised learning show promise in reducing overfitting.
The Future: RL’s Role in Evolving Crypto Markets
Looking ahead to 2025 and beyond, RL could integrate with zero-knowledge proofs for secure, on-chain trading or use multi-agent systems for decentralized market making. With AI hardware improving, expect faster training and more sophisticated agents handling DeFi protocols.
Projects like ReformDAO are already using RL precursors for event forecasting, blending it with unsupervised learning. As crypto matures, RL might bridge traditional finance, optimizing everything from options to liquidity provision.
Wrapping Up: Is RL the Future of Crypto HFT?
Reinforcement learning is transforming high-frequency crypto trading from a rigid, rule-bound game into an adaptive, intelligent pursuit. By learning from the market’s chaos, RL agents offer a competitive edge that’s hard to match. But success hinges on robust design, quality data, and ongoing refinement. If you’re dipping your toes in, start with open-source tools like RLlib or FinRL—experiment in simulations before going live.
In a market where every millisecond counts, RL isn’t just about speed; it’s about smart, resilient decision-making. As crypto continues to evolve, those leveraging RL will likely stay ahead of the curve. What do you think—ready to train your own agent?